Всем привет, давненько я ничего не делал руками тут не писал.
Случилась у меня неприятность — плохо стал работать джойстик управления боковыми зеркалами в машине, а конкретно — сломалась трещётка при кручении: джойстик стал просто вращаться безо всяких усилий. Это сложно объяснить, но как только у вас это произойдёт, вы сразу поймёте, что я имею в виду.
Деталь можно найти в каталоге elcats.ru магазина exist.ru. Новый джойстик стоит каких-то (ну нихрена ж себе!) 12-19 тысяч рублей, потому что провозят их курьеры, вероятно, контрабандой, как Морти — мега-семена.





Код детали для самостоятельного поиска: 5P0959565B. Мне достался джойстик с разборки за 2300, плюс доставка СДЭК 400 рублей денег.
Для замены надо поддеть центральную консоль в передней части с помощью специального инструмента из пластика. Я свой инструмент где-то протерял, поэтому использовал пластиковую карту какого-то банка (тут могла быть ваша реклама), которая сломалась в процессе, и я её выкинул. Приступим!
Алгоритм такой:
- Если у вас зима, прогрейте салон до 20 градусов, чтобы пластик стал гибким, и вытащите ключ зажигания, чтобы максимально обесточить систему.
- Снимаем центральную консоль, поддевая её в передней части.
- Посадочное место консоли, крепления зелёного цвета.
- Вытаскиваем фишку (штекер) из джойстика, нажав на язычок. Джойстик на фото слева.
- Снимаем ручку/крутилку с джойстика с небольшим усилием, потянув на себя (возможно, это делать не надо).
- Вытаскиваем джойстик с посадочного места. На фото рабочий (42/12) и нерабочий (12/15) джойстики. На левом джойстике видны зубцы крепления детали в гнезде.
- Собираем всё в обратном порядке.
По фотографиям всё более-менее должно быть понятно. Если есть вопросы, задавайте быстрее, пока не забыл нюансы.
Если вам не нравятся фотографии, нажмите Ctrl, потом кнопку W на клавиатуре, чтобы их улучшил ИИ.
WordPress: Интерактивный тег <!—more—> без перезагрузки страницы
В начале статьи хочу признаться, что я не верстальщик и не владею PHP, JavaScript или CSS на должном уровне, поэтому всё, что написано ниже, используйте на свой страх и риск. Возможно, это неправильно и надо делать не так. Я не знаю, как надо правильно, учусь самостоятельно, поэтому пишу, как умею хрум-хрум-хрум.
Решил привести в порядок свою главную страницу блога. Не нравятся мне длинные посты, которые нужно долго листать, чтобы перейти к следующему. Изначально рассматривал два варианта:
- Кнопка
[Пропустить пост]для быстрой перемотки к следующему посту и возвращению к предыдущему - Кнопка
[Развернуть]для динамической загрузки остальной части поста после тега<!--more-->.
В итоге выбрал третий путь: весь пост загружается сразу, но часть после тега <!--more--> показывается или скрывается по клику на кнопку [развернуть/свернуть].
Я выбрал этот вариант по двум причинам:
- Скрытая часть поста должна корректно обрабатываться скриптами по событию
onload/onready. - Размер постов у меня небольшой.
Реализация
Для начала нужно выбрать способ получения полного текста поста. Если вызвать get_the_content(), то возвращается только часть до тега. Можно обойти это поведение, используя глобальную переменную $more, но такое решение выглядит как костыль:
function my_the_content() {
global $more;
$prev_more = $more;
$more = 1;
$content = apply_filters('the_content', get_the_content());
$more = $prev_more;
}
Я решил брать текст поста из поля post_content объекта $post и делить его с помощью функции get_extended().
В итоге, я заменил вызов the_content() в своей теме на my_the_content($post) такого вида (код нужно добавить в functions.php вашей темы WordPress):
function my_the_content($post) {
// На странице поста стандартное поведение
if (is_singular()) {
the_content();
return;
}
// Получаем текст целиком из поля post_content и применяем фильтры
$content = apply_filters('the_content', $post->post_content);
// Разбиваем на несколько частей по тегу <!--more-->
$parts = get_extended($content);
// Часть после тега
$extended = $parts['extended'];
// После тега ничего нет, заканчиваем работу
if (empty($extended)) {
return;
}
// Поддержка роботов и тех, кому отключили JavaScript за неуплату
echo '<noscript>';
echo '<div>'.$extended.'</div>';
echo '<style>.post-body {display: none; }</style>';
echo '</noscript>';
// Храним всю дополнительную часть в секции post-body,
// классы expanded/collapsed используются для регулировки видимости элементов
echo '<div class="post-body">';
// Прячем кнопки в отдельном контейнере для удобства
echo '<div class="toggle-buttons">';
// Две кнопки, одна видна, другая спрятана
echo '<div class="toggle-post-body expanded">';
echo '<div class="label expand">развернуть</div>';
echo '</div>';
echo '<div class="toggle-post-body collapsed">';
echo '<div class="label collapse">свернуть</div>';
echo '</div>';
echo '</div>';
// Тело поста спрятано по умолчанию
echo '<div class="post-body-content collapsed">'.$extended.'</div>';
echo '</div>';
}
Стилизация
Теперь стили для блока .post-body. Все изменения затрагивают только элементы внутри него:
/* Элементы с классом collapsed внутри post-body скрыты */
.post-body .collapsed {
display: none;
}
/* Элементы с классом expanded внутри post-body видны */
.post-body .expanded {
display: block;
}
/* Общие настройки для кнопок-переключателей */
.post-body .toggle-post-body .label {
color: #cc6633;
cursor: pointer;
margin-bottom: 0.5em;
border-bottom: 1px dashed;
font-size: 90%;
}
/* Треугольник для кнопки "свернуть" */
.post-body .toggle-post-body .label.collapse:before {
content: '\25BC';/* ▼ */
margin-right: 5px;
}
/* Треугольник для кнопки "развернуть" */
.post-body .toggle-post-body .label.expand:before {
content: '\25B6'; /* ▶ */
margin-right: 5px;
}
Логика на JavaScript:
И, наконец, скрипт, который переключает видимость:
// Добавляем обработку клику по элементам с классом "toggle-post-body"
jQuery('.toggle-post-body').click(function(event){
var nextButton = jQuery(this)
.toggleClass('expanded')
.toggleClass('collapsed')
.siblings('.toggle-post-body');
nextButton
.toggleClass("expanded")
.toggleClass("collapsed");
var contentBlock = nextButton
.closest(".toggle-buttons")
.next('.post-body-content');
contentBlock
.toggleClass("expanded")
.toggleClass("collapsed");
});
Заключение
Подводя итог, логика работы выглядит следующим образом:
- Расширенная часть поста по умолчанию скрыта (класс .collapsed).
- При клике на видимую кнопку (например, «развернуть») запускается скрипт.
- Скрипт переключает видимость у нажатой кнопки (скрывая её) и у соседней (показывая её).
- Одновременно скрипт меняет видимость у блока с контентом.
Недостатки
- Пользователь не может перейти на страницу с самим постом, кроме как кликнув на заголовок.
- Пришлось убрать блок кнопки Social Likes с главной страницы для того, чтобы люди могли делиться контентом в социальных сетях. Но они этого и так не делают, так что невелика потеря.
- Некоторые мои записи используют канвас для рисования с помощью WebGL или JavaScript. Для них пришлось делать уникальный идентификатор канвасов для каждого поста.
- Страница грузит содержимое всех постов, что может быть накладно, если все посты на странице рисуют графику, например.
- Пришлось переписать каждый пост с меткой «Интерактив», чтобы каждый скрипт писал в свой уникальный canvas плюс немного исправить вызов
requestAnimationFrame. Зато выложил все скрипты на GitHub и добавил каждому демонстрационныйindex.html.
UPD: Немного упростил логику. Теперь у меня два элемента типа toggle-post-body. По кнопке их видимость меняется местами. Можете посмотреть исходники плагина b2k-tools с актуальной версией на GitHub.
Раз вы дочитали до конца, как считаете: нужно ли добавить кнопку «свернуть» в конец поста для быстрой навигации?
Вопросы и ответы для собеседования и подготовки Senior C++ разработчика
Всем привет! Решил разложить по полочкам и записать актуальные на 2025 год вопросы и ответы программисту в позиции Senior C++. Вы можете это использовать как для проведения собеседований в качестве интервьюера, так и для подготовки к ним. Считаю, это самая скучная статья на моём сайте, но лучший способ что-то запомнить — это записать и систематизировать свои знания.
Немного о себе: пишу на C++ уже восемнадцатый год и немножко понимаю в программировании.
Кстати, недавно узнал, что человек запоминает 25% любой информации, но надолго. И вот смотрю я на эту прорву текста и думаю — если это всего лишь четверть, то ни фига себе — насколько огромная часть знаний прошла мимо меня.

std::shared_mutex.
Где располагаются переменные, чем инициализированы, область видимости:
int a;
static int b;
int c = 30;
const int d = 20; // без слова "extern" переменная d видна только в этом файле
void function() {
int fa;
int fb = 10;
const int fc = 5;
static int fd; // инициализируется нулём при первом вызове функции
static int fe = 1; // инициализируется единичкой при первом вызове функции
}
Если мы объявляем переменную в глобальном пространстве, то указание static делает видимость этой переменной только в этом файле. Указание константности приводит (в зависимости от желания компилятора) помещение его значения по умолчанию в секцию .rodata исполняемого файла или сразу встраивание этого значения в код вместо переменной. Все переменные объявленные вне функций инициализированы нулём по умолчанию и живут в сегменте памяти BSS, который выделяется и заполняется нулями при запуске программы, его размер записан в исполняемом файле. Не const переменные сохраняют своё значение в сегменте памяти DATA исполняемого файла. Этот сегмент копируется в память компьютера при запуске программы. Все глобальные переменные живут в статической памяти (BSS/DATA/.rodata). Статическая память выделятся при старте программы, имеет постоянный размер и существует в течение всей жизни программы. Размещение переменных по сегментам статической памяти — это поведение на этапе компоновки, описанное в стандартных соглашениях (Application Binary Interface, ABI). Сводная таблица всех переменных из примера выше:
| Переменная | Инициализация | Сегмент памяти | Видимость |
|---|---|---|---|
int a; |
Неявная (0) | BSS | Глобальная |
static int b; |
Неявная (0) | BSS | Файловая |
int c = 30; |
Явная (30) | DATA | Глобальная |
const int d = 20; |
Явная (20) | .rodata или inline | Файловая |
int fa; |
Мусор | стек | Блочная |
int fb = 10; |
Явная (10) | стек | Блочная |
const int fc = 5; |
Явная (5) | стек или inline | Блочная |
static int fd; |
Неявная (0) | BSS | Блочная |
static int fe = 1; |
Явная (1) | DATA | Блочная |
Правила вывода типа для auto
auto по умолчанию создает копию без ссылок и квалификаторов (const, volatile) верхнего уровня. auto сохраняет низкоуровневые квалификаторы (касающиеся указываемых данных), но отбрасывает высокоуровневые (касающиеся самой переменной-указателя).
Пример:
int x = 42;
const int *p1 = &x; // нельзя менять данные, но можно указатель
int *const p2 = &x; // нельзя менять указатель, но можно менять данные
const int *const p3 = &x; // нельзя менять указатель, нельзя менять данные
const int &p4 = x; // ссылка на const int
auto a1 = p1; // const int * - оставили const для данных
auto a2 = p2; // int * - убрали const для указателя
auto a3 = p3; // const int * - оставили const для данных, убрали const для указателя
auto a4 = p4; // int - убрали const, убрали ссылку
В итоге, правила для auto:
- указатели: сохраняют квалификаторы низкого уровня
- ссылки: отбрасывает ссылку, отбрасывает
const
Что такое RAII?
Resource Acquisition Is Initialization — дословно «захват ресурса есть инициализация». В конструкторе захватываем ресурс, в деструкторе освобождаем.
Какие бывают умные указатели?
std::shared_ptr— RAII указатель на объект со счётчиком ссылок. Копирование увеличивает счётчик ссылок, в деструкторе счётчик уменьшается. При достижении нуля освобождает память.std::weak_ptr— слабая ссылка на объект, управляемыйstd::shared_ptr. Не увеличивает счётчик ссылок. Для использования нужно преобразовать вstd::shared_ptrс помощью методаlock(). Полезен, чтобы избежать циклических ссылок междуstd::shared_ptr.std::unique_ptr— указатель с исключительным владением объектом. Запрещено копирование, разрешено только перемещение. Для передачи владения используйтеstd::move. Имеет специализацию для массивов:std::unique_ptr<T[]>.
Почему лучше использовать std::make_shared и std::make_unique, когда возможно?
Во время вычисления параметров конструктора возможно исключение, которое приведёт к утечке памяти. Также std::make_shared выделяет память для объекта и контрольного блока за одну аллокацию. В конце концов, читать удобнее.
NOTE: Более увлечённый в C++ коллега (привет, Евгений!) указал, что есть ситуации, когда использование std::make_shared менее эфективно, чем просто вызов конструктора std::shared_ptr. Это связано с тем, что при использовании std::make_shared остаётся живым контрольный блок, пока жива хоть одна weak_ptr ссылка на объект. Когда используем конструктор такого не происходит. Плюс к этому std::make_shared всегда игнорирует перегруженные операторы new и delete для класса и использует глобальный.
Что происходит при возникновении исключения.
Выполнение функции прерывается, идёт поиск подходящего catch. Сначала в текущей функции, потом идёт последовательно выход наверх по стеку. При выходе вызываются все деструкторы локальных объектов, которые покидают текущую область видимости. Если подходящий catch не найден, то std::terminate(). Если во время раскрутки стека вызовов происходит повторное исключение, то снова std::terminate().
Что происходит при возникновении исключения в конструкторе/деструкторе?
- Если исключение происходит в конструкторе, для уже созданных членов класса вызываются деструкторы, деструктор этого объекта не вызывается, а дальше всё как обычно
- Деструктор неявно объявлен как
noexceptсо стандарта C++11, поэтому любое исключение, покидающее деструктор вызываетstd::terminate(). Также может возникнуть ситуация, если при обработке исключения в деструкторе во время раскрутки стека вызовов произойдёт исключение — то будетstd::terminate()
Почему память выделенная new/malloc будет утечкой, а умный указатель корректно освободит память при вызове исключения?
Потому что происходит раскрутка стека и очистка локальных переменных, выделенных на стеке, плюс вызываются деструкторы этих переменных. Сырой указатель от new/malloc не имеет деструктора и выделен в куче.
В чём особенность placement new?
При использовании placement new деструктор нужно вызывать вручную. Правильный порядок действий:
// 1. Выделили память
void* memory = ::operator new(sizeof(MyClass));
// 2. Создали объект (placement new)
MyClass* obj = new (memory) MyClass();
// 3. Использовали объект
obj->method();
// 4. Вызвали деструктор
obj->~MyClass();
// 5. Освободили память
::operator delete(memory);
Что такое срез исключения? Когда происходит? Как избежать?
Это происходит когда мы пытаемся перехватить исключение по значению, когда тип исключения в catch-блоке является базовым к брошенному исключению, например вот так:
try {
throw MyException(what, extended_data); // наследник std::exception
}
catch (std::exception e) { // тут происходит СРЕЗ
// Значение extended_data утеряно
}
Поэтому лучший путь — это перехватывать исключение по константной ссылке.
try {
throw MyException(what, extended_data); // наследник std::exception
}
catch (const std::exception &e) {
// Сохраняется полная информация об исключении
}
Что происходит при бросании исключения из noexcept метода?
Немедленный вызов std::terminate() и аварийное завершение программы.
Сколько создаётся vtable и vptr в классах и экземплярах классов?
- vtable — создаётся во время компиляции одна для каждого полиморфного класса, хранится в статической памяти
- vptr — создаётся в конструкторе в одном экземпляре в каждом объекте полиморфного класса, хранится внутри объекта. Сначала vptr указывает на таблицу базового класса, потом уже текущего.
Что происходит при вызове виртуального метода в конструкторе?
В конструкторе указатель на таблицу виртуальных методов (vptr) указывает на таблицу текущего класса, значит вызываются методы текущего класса, а не производного. Конструктор производного класса вызывается после конструктора базового. Вызов чисто виртуального метода приведёт к неопределённому поведению или ошибке компиляции.
struct Base {
public:
Base() {
print(); // Вызывается Base::print()
}
virtual void print() { ... }
};
struct Derived : Base {
Derived() { // вызывается Base::Base(), затем Base::print()
print(); // а здесь уже Derived::print()
}
void print() override { ... }
}
В общем, лучше не вызвать виртуальную функцию наследников класса в конструкторах.
Что происходит при вызове виртуального метода в деструкторе?
То же самое, что в вопросе выше. Только в конструкторе производный класс ещё не построен, а в деструкторе производный класс уже разрушен.
Какие бывают касты в C++.
Целую заметку написал, не буду повторяться: Различные касты в C++.
Что такое семантика перемещения (move semantic)?
Механизм, который, начиная с C++11, позволяет эффективно передавать ресурсы между объектами без дорогостоящего копирования. Использование выглядит так:
std::vector<int> a;
a.resize(1000000); // выделяем много памяти
std::vector<int> b = std::move(a); // перемещаем данные, исходный объект в неопределённом состоянии
После выполнения кода объект b владеет данными, объект a находится в валидном, но неопределённом состоянии. Полезно знать, что std::move только преобразует тип в r-value ссылку и ничего никуда не перемещает, реальное перемещение выполняет конструктор перемещения или оператор перемещения.
Что такое RVO и NRVO
Это оптимизации компилятора под названием Copy elision (пропуск копий), которые позволяют избежать лишнего копирования/перемещения при возврате объектов из функций:
- RVO(Return Value Optimization) — оптимизация безымянного возвращаемого значения, гарантировано стандартом C++17:
HeavyObject create() {
return HeavyObject();
}
- NRVO(Named Return Value Optimization) — оптимизация именованного возвращаемого значения, когда возвращается именованная локальная переменная. Обратите внимание — использование
std::moveпри возврате значения ломает эту оптимизацию!
HeavyObject create() {
HeavyObject a;
return a;
}
Что такое и как использовать std::future/std::promise? В каких случаях std::future бросает ошибку?
future/promise — это механизм передачи данных или исключений между потоками. Одному std::promise соответствует один std::future.
std::promise— устанавливает значение (set_value()) или исключение (set_exception()), которое извлекается с помощьюstd::future.std::future— предоставляет доступ к результату (get()), записанному черезstd::promise. Методget()вызывает исключение, еслиstd::promiseуничтожен без установки значения или исключения. Повторный вызовget()также вызовет ошибку.
Пример для наглядности:
#include <iostream>
#include <future>
#include <thread>
int main() {
auto worker = [](auto p) {
try {
p.set_value("Hello world!");
// Делаем что-то вызывающее исключение
}
catch(...) {
// Передаём исключение
p.set_exception(std::current_exception());
}
};
std::promise<std::string> promise;
auto f = promise.get_future();
// Передаём promise по значению в поток с помощью перемещения
std::thread t(worker, std::move(promise));
try {
std::cout << f.get() << std::endl;
}
catch (const std::exception &e) {
std::cerr << "Exception : " << e.what() << std::endl;
}
t.join();
}
std::future можно использовать для получения значения только один раз и нельзя копировать, если хотите это изменить, создайте std::shared_future с помощью метода std::future::share() — этот класс лишён таких недостатков.
Что такое deadlock и как происходит?
Блокирование потоков в ожидании друг друга. Происходит, когда в потоке A блокируется мьютекс a, потом b. А в потоке B сначала мьютекс b, потом a. Исправляется использованием std::scoped_lock или одинаковым порядком блокирования мьютексов.
Зачем нужен std::shared_mutex?
Вместе с std::shared_lock и std::unique_lock std::shared_mutex обеспечивает множественный доступ (на чтение) при использовании std::shared_lock и эксклюзивный доступ (на запись) при использовании std::unique_lock соответственно.
Пример для наглядности:
std::shared_mutex mutex;
std::vector<int> data;
void write(int value) {
std::unique_lock lock(mutex); // эксклюзивная блокировка
data.push_back(value);
}
int read(size_t index) {
std::shared_lock lock(mutex); // разделяемая блокировка
return data.at(index);
}
Зачем нужно указание memory_order в объектах типа std::atomic? Какие бывают memory_order?
Если вкратце, то memory_order позволяет контролировать модель памяти для атомарных операций. Модель памяти определяет, как операции чтения и записи памяти могут быть переупорядочены компилятором и процессором для оптимизации. Начиная от самой слабой гарантии std::memory_order_relaxed и заканчивая самой строгой std::memory_order_seq_cst (по умолчанию). Если хотите подробнее вникнуть в тему, то вот сорокаминутное видео с объяснением от разработчика из Яндекса:
Чем процесс отличается от потока?
Изолированностью в первую очередь. Процессы имеют свои ресурсы, потоки делят ресурсы одного процесса. Падение одного потока приводит к завершению всего процесса. Завершение процесса никак не затрагивает другие процессы.
Что будет если вызвать new с огромным куском памяти?
Произойдёт вызов исключения std::bad_alloc, можно использовать new (std::nothrow) если хочется получить nullptr в случае неудачи.
Как работает алгоритм std::remove/std::remove_if
Пробегаемся по контейнеру слева направо двумя итераторами:
- первый итератор (
first) указывает на текущий элемент - второй (
result) указывает на позицию куда сохранять подходящие элементы.
Реализация алгоритма для наглядности:
template<typename ForwardIt, typename UnaryPredicate>
ForwardIt remove_if(ForwardIt first, ForwardIt last, UnaryPredicate p) {
ForwardIt result = first;
for (; first != last; ++first) {
if (!p(*first)) {
if (result != first) {
*result = std::move(*first);
}
++result;
}
}
return result;
}
Какие бывают контейнеры STL. Устройство и сложность операций поиска/вставки/удаления.
std::vector— выделяет непрерывный кусок памяти, если не хватает места, то выделяется бОльший кусок, старые данные копируются туда, доступ имеет сложность O(1), вставка в конец имеет амортизированную сложность O(1), вставка в начало/середину требует сдвига всех данных вправо и имеет сложность O(n). Эффективно использует кеш процессора. Имеет возможность доступа по индексу.std::list— двусвязный список, поиск O(n), доступ по индексу O(n), вставка O(1) при наличии итератора, удаление O(1) при наличии итератора, доступ к элементам по итератору.std::forward_list— односвязный список, аналогиченstd::list, но занимает меньше памяти. Может вставлять/удалять только после известного элемента.std::deque— двусторонняя очередь, реализуется как массив указателей на блоки, доступ O(1), вставка/удаление с начала/конца O(1), в середине O(n).std::unordered_set/std::unordered_map— хеш-таблица из бакетов, поиск, вставка, удаление O(1) в среднем случае, O(n) в худшем (при коллизиях), элементы без сортировки.std::set/std::map— красно-черные деревья, поиск/вставка/удаление O(log n). Элементы отсортированы.std::array— аналог сишного массива фиксированного размера с плюшками STL в виде итераторов и деструктораstd::span— интерфейс для работы с непрерывными последовательностями данных без владения этими даннымиstd::string_view— аналогstd::spanдляstd::string, доступ к данным строки без владения
Что такое универсальная ссылка, что такое perfect forwarding?
Perfect forwarding — это способ передать аргумент в другую функцию точно так, как он был получен:
lvalueостаётсяlvaluervalueостаётсяrvalueconstостаётсяconst
Выглядит так:
template<typename T>
void foo(T&&value) // T&& является универсальной ссылкой
{
bar(std::forward<T>(value));
}
Тут есть важный нюанс для шаблонных классов, легко ошибиться:
template<typename T>
class A {
void foo(T&&value) // это не универсальная ссылка
{
bar(std::forward<T>(value));
}
template<typename U>
void foo2(U&&value) // а здесь всё работает правильно
{
bar(std::forward<U>(value));
}
}
Требований для perfect forwarding два:
- Это должна быть шаблонная функция с универсальной ссылкой
- использование
std::forwardдля передачи параметров дальше
Почему так сделано? Очевидно, потому, что создатели C++ ненавидят людей и желают им всего плохого, а если без шуток, то, чтобы избежать проблем при инстанцировании шаблона класса ну и щепотка ненависти к людям, конечно. Кстати T&& становится универсальной ссылкой, только в контексте вывода параметров шаблона.
P.S. Благодарю создателей Markdown за синтаксис языка разметки, всё форматирование сделано с помощью него.
Обновляем краткое содержания статей в блоге с помощью ИИ, денег, bash и wp-cli
Всем привет! Если вы не первый раз на моём сайте, то могли заметить, что краткое содержание заметок содержит первые n слов (вроде, 22) из заметки безо всякого осмысления. По крайней мере, так было до недавнего времени.
Поскольку сейчас наступил XXI век, то пора передать формирование краткого содержания заметок на откуп искусственному интеллекту.
Делать плагин мне откровенно не хочется, поэтому я обновил все заметки с помощью bash-скрипта, запрашивая краткое содержание статьи через curl у Yandex GPT через их API.
Алгоритм такой:
- получаю ID всех статей блога с помощью wp-cli
- для каждой статьи блога, отправляю её содержимое в Yandex GPT с помощью API
- получаю краткую выжимку статьи и показываю пользователю
- если он согласен с содержимым, то обновляю поле
post_excerptу статьи - вывожу
post_excerptв мета полеdescriptionпри формировании статьи в разделе - ???
- PROFIT
Для регистрации и работы с Yandex GPT нужно немного денег, я потратил 50 рублей. Регистрация и получение идентификаторов каталога (folder_id) и API ключа (api_key) найдёте в этой статье на «Хабре»: (Как подключить Yandex GPT к своему проекту на Python)[https://habr.com/ru/articles/780008/].
Добавил в скрипт подтверждение каждого шага от пользователя, потому что иногда ИИ выдаёт какую-то политкорректную дичь типа «Я не могу обсуждать эту тему. Давайте поговорим о чём-нибудь ещё» на простые запросы, а также он не умеет работать с видео. И добавил проверку, что цитата не заполнена для поста, чтобы лишний раз не тратить запросы к ИИ.
#!/usr/bin/env bash
# Конфигурация
FOLDER_ID="folder_id"
API_KEY="api_key"
API_URL="https://llm.api.cloud.yandex.net/foundationModels/v1/completion"
wrap_for_yandexgpt() {
local text="$1"
jq -n \
--arg text "$text" \
--arg folder "$FOLDER_ID" \
'{
"modelUri": "gpt://\($folder)/yandexgpt-lite",
"completionOptions": {
"stream": false,
"temperature": 0.3,
"maxTokens": "2000"
},
"messages": [
{
"role": "user",
"text": $text
}
]
}'
}
# Функция для отправки запроса
create_post_excerpt() {
local content="$1"
local prompt="Сделай краткое метаописание статьи (до 60 слов):\n\n$content"
local json_payload
json_payload=$(wrap_for_yandexgpt "$prompt")
# Выполняем запрос и сохраняем ответ в переменную
local response
response=$(curl -s -w "\nHTTPSTATUS:%{http_code}" -X POST -H "Content-Type: application/json" -H "Authorization: Api-Key $API_KEY" -H "x-folder-id: $FOLDER_ID" -d "$json_payload" $API_URL)
# Проверяем, что curl выполнился успешно
if [ $? -ne 0 ]; then
echo "Ошибка выполнения curl" >&2
return 1
fi
# Извлекаем HTTP код и тело ответа
local http_code
local body
http_code=$(echo "$response" | sed -n 's/HTTPSTATUS://p')
body=$(echo "$response" | sed '$d')
# Проверяем HTTP-код
if [ "$http_code" -ne 200 ]; then
echo "ошибка HTTP: $http_code" >&2
return 1
fi
# Проверяем наличие ошибки в теле ответа
if echo "$body" | jq -e '.error' >/dev/null 2>&1; then
local error_msg
error_msg=$(echo "$body" | jq -r '.error.message // .error')
echo "ошибка API: $error_msg" >&2
return 1
fi
# Извлекаем текст
local result
result=$(echo "$body" | jq -r '.result.alternatives[0].message.text // empty')
if [ -z "$result" ]; then
echo "пустой ответ от API" >&2
return 1
fi
local status
status=$(echo "$body" | jq -r '.result.alternatives[0].status // empty')
if [ "$status" == "ALTERNATIVE_STATUS_CONTENT_FILTER" ]; then
echo "[cencored]"
return 1
fi
echo "$result"
return 0
}
update_post_excerpt() {
local post_id=$1
local excerpt="$2"
wp --allow-root post update "$post_id" --post_excerpt="$excerpt"
}
get_post_excerpt() {
local post_id=$1
wp --allow-root post get "$post_id" --field=post_excerpt
}
get_post_title() {
local posts_data="$1"
local post_id="$2"
echo "$posts_data" | jq ".[] | select(.ID==$post_id) | .post_title"
}
get_post_content() {
local posts_data="$1"
local post_id="$2"
echo "$posts_data" | jq ".[] | select(.ID==$post_id) | .post_content"
}
cd wordpress_dir || exit
posts_data=$(wp post list --allow-root --post_type=post --fields=ID,post_title,post_content,post_excerpt --format=json --post_status=publish | jq 'map(select(.post_excerpt=="" or .post_excerpt==null))')
post_ids=$(echo "$posts_data" | jq .[].ID)
for post_id in $post_ids; do
title=$(get_post_title "$posts_data" "$post_id")
echo "ЗАГОЛОВОК: $title"
content=$(get_post_content "$posts_data" "$post_id")
post_excerpt=$(create_post_excerpt "$content")
exit_code=$?
if [ $exit_code -ne 0 ]; then
echo "ОШИБКА ПОЛУЧЕНИЯ ЦИТАТЫ: $post_excerpt"
echo
continue
fi
echo "ЦИТАТА: \"$post_excerpt\""
while true; do
read -r -n1 -p "Обновить цитату? (y - да, n - пропустить, q - выход) " choice
choice=$(echo "$choice" | tr '[:upper:]' '[:lower:]')
echo
case $choice in
y)
update_post_excerpt "$post_id" "$post_excerpt"
break
;;
n)
break
;;
q)
exit 0
;;
*)
continue
;;
esac
done
echo
done
cd - || exit
Всё, что делает этот скрипт он делает только под вашу личную ответственность. Я никаких гарантий не даю и ответственности за результат не несу. Примерно половину скрипта написал DeepSeek, претензии к нему.
UPD. Выложил скрипты на GitHub.
Добавляем подсветку нового языка в плагин Prismatic+Prism.js
Всем привет! Понадобилось мне вставить CMakeLists.txt в мою заметку с подсветкой кода. В блоге она включена с помощью плагина Prismatic и библиотеки Prism.js c темой «Tomorow Night», если вам интересно. И так родилась эта инструкция по добавлению нового языка (в нашем случае CMake) в плагин. Все работы проходят в папке плагина wp-content/plugins/prismatic, порядок действий следующий:
- Переходим на страницу скачивания Prism. Выбираем minified версию и только тот язык, который вам нужен, у меня был язык cmake и получился файл на 18 килобайт.
- Вставляем по адресу
./lib/prism/js/lang-cmake.jsкусок кода сPrism.language.cmake. Пример lang-cmake.js - Открываем
./inc/resources-enqueue.phpв функцииprismatic_prism_classesв первом массиве после'language-bash'вставляем'language-cmake', во втором после'lang-bash'вставляем'lang-cmake'.
Мне кажется, первый массив отвечает за название CSS класса, а второй — название JS файла, но я не уверен, потому что я ненастоящий PHP программист.
Патч под спойлером к с версии 3.6:
Index: inc/resources-enqueue.php
===================================================================
--- inc/resources-enqueue.php (revision 3415040)
+++ inc/resources-enqueue.php (working copy)
@@ -458,6 +458,7 @@ function prismatic_prism_classes() {
'language-batch',
'language-c',
'language-clike',
+ 'language-cmake',
'language-coffeescript',
'language-cpp',
'language-csharp',
@@ -542,6 +543,7 @@ function prismatic_prism_classes() {
'lang-batch',
'lang-c',
'lang-clike',
+ 'lang-cmake',
'lang-coffeescript',
'lang-cpp',
'lang-csharp',
@@ -651,4 +653,4 @@ function prismatic_get_current_screen_id() {
return false;
-}
\ No newline at end of file
+}
Index: lib/prism/js/lang-cmake.js
===================================================================
--- lib/prism/js/lang-cmake.js (nonexistent)
+++ lib/prism/js/lang-cmake.js (working copy)
@@ -0,0 +1 @@
+Prism.languages.cmake={comment:/#.*/,string:{pattern:/"(?:[^\\"]|\\.)*"/,greedy:!0,inside:{interpolation:{pattern:/\$\{(?:[^{}$]|\$\{[^{}$]*\})*\}/,inside:{punctuation:/\$\{|\}/,variable:/\w+/}}}},variable:/\b(?:CMAKE_\w+|\w+_(?:(?:BINARY|SOURCE)_DIR|DESCRIPTION|HOMEPAGE_URL|ROOT|VERSION(?:_MAJOR|_MINOR|_PATCH|_TWEAK)?)|(?:ANDROID|APPLE|BORLAND|BUILD_SHARED_LIBS|CACHE|CPACK_(?:ABSOLUTE_DESTINATION_FILES|COMPONENT_INCLUDE_TOPLEVEL_DIRECTORY|ERROR_ON_ABSOLUTE_INSTALL_DESTINATION|INCLUDE_TOPLEVEL_DIRECTORY|INSTALL_DEFAULT_DIRECTORY_PERMISSIONS|INSTALL_SCRIPT|PACKAGING_INSTALL_PREFIX|SET_DESTDIR|WARN_ON_ABSOLUTE_INSTALL_DESTINATION)|CTEST_(?:BINARY_DIRECTORY|BUILD_COMMAND|BUILD_NAME|BZR_COMMAND|BZR_UPDATE_OPTIONS|CHANGE_ID|CHECKOUT_COMMAND|CONFIGURATION_TYPE|CONFIGURE_COMMAND|COVERAGE_COMMAND|COVERAGE_EXTRA_FLAGS|CURL_OPTIONS|CUSTOM_(?:COVERAGE_EXCLUDE|ERROR_EXCEPTION|ERROR_MATCH|ERROR_POST_CONTEXT|ERROR_PRE_CONTEXT|MAXIMUM_FAILED_TEST_OUTPUT_SIZE|MAXIMUM_NUMBER_OF_(?:ERRORS|WARNINGS)|MAXIMUM_PASSED_TEST_OUTPUT_SIZE|MEMCHECK_IGNORE|POST_MEMCHECK|POST_TEST|PRE_MEMCHECK|PRE_TEST|TESTS_IGNORE|WARNING_EXCEPTION|WARNING_MATCH)|CVS_CHECKOUT|CVS_COMMAND|CVS_UPDATE_OPTIONS|DROP_LOCATION|DROP_METHOD|DROP_SITE|DROP_SITE_CDASH|DROP_SITE_PASSWORD|DROP_SITE_USER|EXTRA_COVERAGE_GLOB|GIT_COMMAND|GIT_INIT_SUBMODULES|GIT_UPDATE_CUSTOM|GIT_UPDATE_OPTIONS|HG_COMMAND|HG_UPDATE_OPTIONS|LABELS_FOR_SUBPROJECTS|MEMORYCHECK_(?:COMMAND|COMMAND_OPTIONS|SANITIZER_OPTIONS|SUPPRESSIONS_FILE|TYPE)|NIGHTLY_START_TIME|P4_CLIENT|P4_COMMAND|P4_OPTIONS|P4_UPDATE_OPTIONS|RUN_CURRENT_SCRIPT|SCP_COMMAND|SITE|SOURCE_DIRECTORY|SUBMIT_URL|SVN_COMMAND|SVN_OPTIONS|SVN_UPDATE_OPTIONS|TEST_LOAD|TEST_TIMEOUT|TRIGGER_SITE|UPDATE_COMMAND|UPDATE_OPTIONS|UPDATE_VERSION_ONLY|USE_LAUNCHERS)|CYGWIN|ENV|EXECUTABLE_OUTPUT_PATH|GHS-MULTI|IOS|LIBRARY_OUTPUT_PATH|MINGW|MSVC(?:10|11|12|14|60|70|71|80|90|_IDE|_TOOLSET_VERSION|_VERSION)?|MSYS|PROJECT_NAME|UNIX|WIN32|WINCE|WINDOWS_PHONE|WINDOWS_STORE|XCODE))\b/,property:/\b(?:cxx_\w+|(?:ARCHIVE_OUTPUT_(?:DIRECTORY|NAME)|COMPILE_DEFINITIONS|COMPILE_PDB_NAME|COMPILE_PDB_OUTPUT_DIRECTORY|EXCLUDE_FROM_DEFAULT_BUILD|IMPORTED_(?:IMPLIB|LIBNAME|LINK_DEPENDENT_LIBRARIES|LINK_INTERFACE_LANGUAGES|LINK_INTERFACE_LIBRARIES|LINK_INTERFACE_MULTIPLICITY|LOCATION|NO_SONAME|OBJECTS|SONAME)|INTERPROCEDURAL_OPTIMIZATION|LIBRARY_OUTPUT_DIRECTORY|LIBRARY_OUTPUT_NAME|LINK_FLAGS|LINK_INTERFACE_LIBRARIES|LINK_INTERFACE_MULTIPLICITY|LOCATION|MAP_IMPORTED_CONFIG|OSX_ARCHITECTURES|OUTPUT_NAME|PDB_NAME|PDB_OUTPUT_DIRECTORY|RUNTIME_OUTPUT_DIRECTORY|RUNTIME_OUTPUT_NAME|STATIC_LIBRARY_FLAGS|VS_CSHARP|VS_DOTNET_REFERENCEPROP|VS_DOTNET_REFERENCE|VS_GLOBAL_SECTION_POST|VS_GLOBAL_SECTION_PRE|VS_GLOBAL|XCODE_ATTRIBUTE)_\w+|\w+_(?:CLANG_TIDY|COMPILER_LAUNCHER|CPPCHECK|CPPLINT|INCLUDE_WHAT_YOU_USE|OUTPUT_NAME|POSTFIX|VISIBILITY_PRESET)|ABSTRACT|ADDITIONAL_MAKE_CLEAN_FILES|ADVANCED|ALIASED_TARGET|ALLOW_DUPLICATE_CUSTOM_TARGETS|ANDROID_(?:ANT_ADDITIONAL_OPTIONS|API|API_MIN|ARCH|ASSETS_DIRECTORIES|GUI|JAR_DEPENDENCIES|NATIVE_LIB_DEPENDENCIES|NATIVE_LIB_DIRECTORIES|PROCESS_MAX|PROGUARD|PROGUARD_CONFIG_PATH|SECURE_PROPS_PATH|SKIP_ANT_STEP|STL_TYPE)|ARCHIVE_OUTPUT_DIRECTORY|ATTACHED_FILES|ATTACHED_FILES_ON_FAIL|AUTOGEN_(?:BUILD_DIR|ORIGIN_DEPENDS|PARALLEL|SOURCE_GROUP|TARGETS_FOLDER|TARGET_DEPENDS)|AUTOMOC|AUTOMOC_(?:COMPILER_PREDEFINES|DEPEND_FILTERS|EXECUTABLE|MACRO_NAMES|MOC_OPTIONS|SOURCE_GROUP|TARGETS_FOLDER)|AUTORCC|AUTORCC_EXECUTABLE|AUTORCC_OPTIONS|AUTORCC_SOURCE_GROUP|AUTOUIC|AUTOUIC_EXECUTABLE|AUTOUIC_OPTIONS|AUTOUIC_SEARCH_PATHS|BINARY_DIR|BUILDSYSTEM_TARGETS|BUILD_RPATH|BUILD_RPATH_USE_ORIGIN|BUILD_WITH_INSTALL_NAME_DIR|BUILD_WITH_INSTALL_RPATH|BUNDLE|BUNDLE_EXTENSION|CACHE_VARIABLES|CLEAN_NO_CUSTOM|COMMON_LANGUAGE_RUNTIME|COMPATIBLE_INTERFACE_(?:BOOL|NUMBER_MAX|NUMBER_MIN|STRING)|COMPILE_(?:DEFINITIONS|FEATURES|FLAGS|OPTIONS|PDB_NAME|PDB_OUTPUT_DIRECTORY)|COST|CPACK_DESKTOP_SHORTCUTS|CPACK_NEVER_OVERWRITE|CPACK_PERMANENT|CPACK_STARTUP_SHORTCUTS|CPACK_START_MENU_SHORTCUTS|CPACK_WIX_ACL|CROSSCOMPILING_EMULATOR|CUDA_EXTENSIONS|CUDA_PTX_COMPILATION|CUDA_RESOLVE_DEVICE_SYMBOLS|CUDA_SEPARABLE_COMPILATION|CUDA_STANDARD|CUDA_STANDARD_REQUIRED|CXX_EXTENSIONS|CXX_STANDARD|CXX_STANDARD_REQUIRED|C_EXTENSIONS|C_STANDARD|C_STANDARD_REQUIRED|DEBUG_CONFIGURATIONS|DEFINE_SYMBOL|DEFINITIONS|DEPENDS|DEPLOYMENT_ADDITIONAL_FILES|DEPLOYMENT_REMOTE_DIRECTORY|DISABLED|DISABLED_FEATURES|ECLIPSE_EXTRA_CPROJECT_CONTENTS|ECLIPSE_EXTRA_NATURES|ENABLED_FEATURES|ENABLED_LANGUAGES|ENABLE_EXPORTS|ENVIRONMENT|EXCLUDE_FROM_ALL|EXCLUDE_FROM_DEFAULT_BUILD|EXPORT_NAME|EXPORT_PROPERTIES|EXTERNAL_OBJECT|EchoString|FAIL_REGULAR_EXPRESSION|FIND_LIBRARY_USE_LIB32_PATHS|FIND_LIBRARY_USE_LIB64_PATHS|FIND_LIBRARY_USE_LIBX32_PATHS|FIND_LIBRARY_USE_OPENBSD_VERSIONING|FIXTURES_CLEANUP|FIXTURES_REQUIRED|FIXTURES_SETUP|FOLDER|FRAMEWORK|Fortran_FORMAT|Fortran_MODULE_DIRECTORY|GENERATED|GENERATOR_FILE_NAME|GENERATOR_IS_MULTI_CONFIG|GHS_INTEGRITY_APP|GHS_NO_SOURCE_GROUP_FILE|GLOBAL_DEPENDS_DEBUG_MODE|GLOBAL_DEPENDS_NO_CYCLES|GNUtoMS|HAS_CXX|HEADER_FILE_ONLY|HELPSTRING|IMPLICIT_DEPENDS_INCLUDE_TRANSFORM|IMPORTED|IMPORTED_(?:COMMON_LANGUAGE_RUNTIME|CONFIGURATIONS|GLOBAL|IMPLIB|LIBNAME|LINK_DEPENDENT_LIBRARIES|LINK_INTERFACE_(?:LANGUAGES|LIBRARIES|MULTIPLICITY)|LOCATION|NO_SONAME|OBJECTS|SONAME)|IMPORT_PREFIX|IMPORT_SUFFIX|INCLUDE_DIRECTORIES|INCLUDE_REGULAR_EXPRESSION|INSTALL_NAME_DIR|INSTALL_RPATH|INSTALL_RPATH_USE_LINK_PATH|INTERFACE_(?:AUTOUIC_OPTIONS|COMPILE_DEFINITIONS|COMPILE_FEATURES|COMPILE_OPTIONS|INCLUDE_DIRECTORIES|LINK_DEPENDS|LINK_DIRECTORIES|LINK_LIBRARIES|LINK_OPTIONS|POSITION_INDEPENDENT_CODE|SOURCES|SYSTEM_INCLUDE_DIRECTORIES)|INTERPROCEDURAL_OPTIMIZATION|IN_TRY_COMPILE|IOS_INSTALL_COMBINED|JOB_POOLS|JOB_POOL_COMPILE|JOB_POOL_LINK|KEEP_EXTENSION|LABELS|LANGUAGE|LIBRARY_OUTPUT_DIRECTORY|LINKER_LANGUAGE|LINK_(?:DEPENDS|DEPENDS_NO_SHARED|DIRECTORIES|FLAGS|INTERFACE_LIBRARIES|INTERFACE_MULTIPLICITY|LIBRARIES|OPTIONS|SEARCH_END_STATIC|SEARCH_START_STATIC|WHAT_YOU_USE)|LISTFILE_STACK|LOCATION|MACOSX_BUNDLE|MACOSX_BUNDLE_INFO_PLIST|MACOSX_FRAMEWORK_INFO_PLIST|MACOSX_PACKAGE_LOCATION|MACOSX_RPATH|MACROS|MANUALLY_ADDED_DEPENDENCIES|MEASUREMENT|MODIFIED|NAME|NO_SONAME|NO_SYSTEM_FROM_IMPORTED|OBJECT_DEPENDS|OBJECT_OUTPUTS|OSX_ARCHITECTURES|OUTPUT_NAME|PACKAGES_FOUND|PACKAGES_NOT_FOUND|PARENT_DIRECTORY|PASS_REGULAR_EXPRESSION|PDB_NAME|PDB_OUTPUT_DIRECTORY|POSITION_INDEPENDENT_CODE|POST_INSTALL_SCRIPT|PREDEFINED_TARGETS_FOLDER|PREFIX|PRE_INSTALL_SCRIPT|PRIVATE_HEADER|PROCESSORS|PROCESSOR_AFFINITY|PROJECT_LABEL|PUBLIC_HEADER|REPORT_UNDEFINED_PROPERTIES|REQUIRED_FILES|RESOURCE|RESOURCE_LOCK|RULE_LAUNCH_COMPILE|RULE_LAUNCH_CUSTOM|RULE_LAUNCH_LINK|RULE_MESSAGES|RUNTIME_OUTPUT_DIRECTORY|RUN_SERIAL|SKIP_AUTOGEN|SKIP_AUTOMOC|SKIP_AUTORCC|SKIP_AUTOUIC|SKIP_BUILD_RPATH|SKIP_RETURN_CODE|SOURCES|SOURCE_DIR|SOVERSION|STATIC_LIBRARY_FLAGS|STATIC_LIBRARY_OPTIONS|STRINGS|SUBDIRECTORIES|SUFFIX|SYMBOLIC|TARGET_ARCHIVES_MAY_BE_SHARED_LIBS|TARGET_MESSAGES|TARGET_SUPPORTS_SHARED_LIBS|TESTS|TEST_INCLUDE_FILE|TEST_INCLUDE_FILES|TIMEOUT|TIMEOUT_AFTER_MATCH|TYPE|USE_FOLDERS|VALUE|VARIABLES|VERSION|VISIBILITY_INLINES_HIDDEN|VS_(?:CONFIGURATION_TYPE|COPY_TO_OUT_DIR|DEBUGGER_(?:COMMAND|COMMAND_ARGUMENTS|ENVIRONMENT|WORKING_DIRECTORY)|DEPLOYMENT_CONTENT|DEPLOYMENT_LOCATION|DOTNET_REFERENCES|DOTNET_REFERENCES_COPY_LOCAL|INCLUDE_IN_VSIX|IOT_STARTUP_TASK|KEYWORD|RESOURCE_GENERATOR|SCC_AUXPATH|SCC_LOCALPATH|SCC_PROJECTNAME|SCC_PROVIDER|SDK_REFERENCES|SHADER_(?:DISABLE_OPTIMIZATIONS|ENABLE_DEBUG|ENTRYPOINT|FLAGS|MODEL|OBJECT_FILE_NAME|OUTPUT_HEADER_FILE|TYPE|VARIABLE_NAME)|STARTUP_PROJECT|TOOL_OVERRIDE|USER_PROPS|WINRT_COMPONENT|WINRT_EXTENSIONS|WINRT_REFERENCES|XAML_TYPE)|WILL_FAIL|WIN32_EXECUTABLE|WINDOWS_EXPORT_ALL_SYMBOLS|WORKING_DIRECTORY|WRAP_EXCLUDE|XCODE_(?:EMIT_EFFECTIVE_PLATFORM_NAME|EXPLICIT_FILE_TYPE|FILE_ATTRIBUTES|LAST_KNOWN_FILE_TYPE|PRODUCT_TYPE|SCHEME_(?:ADDRESS_SANITIZER|ADDRESS_SANITIZER_USE_AFTER_RETURN|ARGUMENTS|DISABLE_MAIN_THREAD_CHECKER|DYNAMIC_LIBRARY_LOADS|DYNAMIC_LINKER_API_USAGE|ENVIRONMENT|EXECUTABLE|GUARD_MALLOC|MAIN_THREAD_CHECKER_STOP|MALLOC_GUARD_EDGES|MALLOC_SCRIBBLE|MALLOC_STACK|THREAD_SANITIZER(?:_STOP)?|UNDEFINED_BEHAVIOUR_SANITIZER(?:_STOP)?|ZOMBIE_OBJECTS))|XCTEST)\b/,keyword:/\b(?:add_compile_definitions|add_compile_options|add_custom_command|add_custom_target|add_definitions|add_dependencies|add_executable|add_library|add_link_options|add_subdirectory|add_test|aux_source_directory|break|build_command|build_name|cmake_host_system_information|cmake_minimum_required|cmake_parse_arguments|cmake_policy|configure_file|continue|create_test_sourcelist|ctest_build|ctest_configure|ctest_coverage|ctest_empty_binary_directory|ctest_memcheck|ctest_read_custom_files|ctest_run_script|ctest_sleep|ctest_start|ctest_submit|ctest_test|ctest_update|ctest_upload|define_property|else|elseif|enable_language|enable_testing|endforeach|endfunction|endif|endmacro|endwhile|exec_program|execute_process|export|export_library_dependencies|file|find_file|find_library|find_package|find_path|find_program|fltk_wrap_ui|foreach|function|get_cmake_property|get_directory_property|get_filename_component|get_property|get_source_file_property|get_target_property|get_test_property|if|include|include_directories|include_external_msproject|include_guard|include_regular_expression|install|install_files|install_programs|install_targets|link_directories|link_libraries|list|load_cache|load_command|macro|make_directory|mark_as_advanced|math|message|option|output_required_files|project|qt_wrap_cpp|qt_wrap_ui|remove|remove_definitions|return|separate_arguments|set|set_directory_properties|set_property|set_source_files_properties|set_target_properties|set_tests_properties|site_name|source_group|string|subdir_depends|subdirs|target_compile_definitions|target_compile_features|target_compile_options|target_include_directories|target_link_directories|target_link_libraries|target_link_options|target_sources|try_compile|try_run|unset|use_mangled_mesa|utility_source|variable_requires|variable_watch|while|write_file)(?=\s*\()\b/,boolean:/\b(?:FALSE|OFF|ON|TRUE)\b/,namespace:/\b(?:INTERFACE|PRIVATE|PROPERTIES|PUBLIC|SHARED|STATIC|TARGET_OBJECTS)\b/,operator:/\b(?:AND|DEFINED|EQUAL|GREATER|LESS|MATCHES|NOT|OR|STREQUAL|STRGREATER|STRLESS|VERSION_EQUAL|VERSION_GREATER|VERSION_LESS)\b/,inserted:{pattern:/\b\w+::\w+\b/,alias:"class-name"},number:/\b\d+(?:\.\d+)*\b/,function:/\b[a-z_]\w*(?=\s*\()\b/i,punctuation:/[()>}]|\$[<{]/};
\ No newline at end of file
UPD: Послал патч автору плагина Prismatic, так что есть вероятность, что подсветка cmake появится в следующих версиях, но это не точно.
Подключение git репозитория в CMake
Всем привет, недавно изучал либу SFML и с удивлением обнаружил, что её можно подключить в CMakeLists.txt с помощью команды FetchContent следующим образом:
cmake_minimum_required(VERSION 3.28)
project(main LANGUAGES CXX)
include(FetchContent)
FetchContent_Declare(SFML
GIT_REPOSITORY https://github.com/SFML/SFML.git
GIT_TAG 3.0.2
GIT_SHALLOW ON
EXCLUDE_FROM_ALL
SYSTEM)
FetchContent_MakeAvailable(SFML)
add_executable(main src/main.cpp)
target_compile_features(main PRIVATE cxx_std_17)
target_link_libraries(main PRIVATE SFML::Graphics)
И при создании файлов для сборки, CMake самостоятельно скачает и подключит SFML к вашему проекту — чистая магия, на мой взгляд.
Как я тестовое задание делал
В конце сентября сходил на собеседование в некую компанию и получил тестовое задание сроком на семь дней. При этом работу предлагали в офисе. Но есть нюансы!
Во-первых, за время работы в «Газпром-Медиа» я отвык работать в офисе. Во-вторых, я уверен, что выполнение тестового задания должно быть оплачено, тем более это целый проект. В-третьих, что-то мне подсказывало, что тестовое задание не примут в любом случае, потому что я не сказал способ нахождения пересечения луча со сферой, да и манера общения в целом мне не понравилась. Тем не менее, с целью узнать что-то новое и в качестве разминки для мозгов, тестовое задание таки взялся выполнять. Ниже расскажу, как это было.
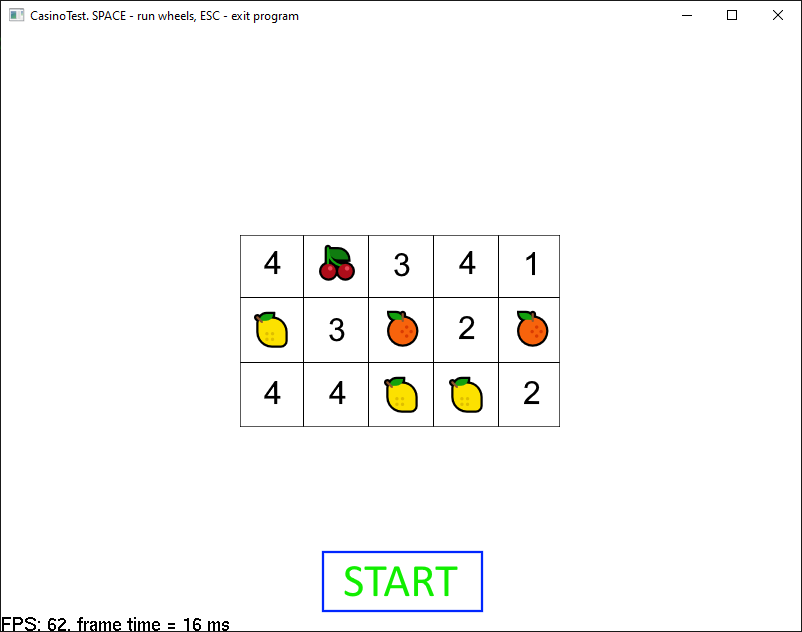
Если описать общими словами задание, то оно звучит так: сделать приложение, имитирующее джекпот автомат с пятью барабанами, которые должны вращаться при нажатии анимированной кнопки «START» и замедляться по очереди спустя 4-5 секунд.
Суббота (утро, за шесть дней до дедлайна)
- В основном составлял план решения задачи.
- Загуглил, как работать с OpenGL на Desktop: с помощью GLUT (который устарел и вместо него берут FreeGLUT) и GLEW. Всегда использовал только мобильную embedded версию OpenGL на мобильных девайсах или WebGL. Для загрузки картинок выбрал библиотеку stb, потому что ранее с ней работал и в ней всего один хедер-файл.
- Создал проект с помощью CMake и скомпилировал его в QtCreator, потому что в компании использовали в основном его.
- Сделал пустое окошко и загрузку пиксельных данных из любого файла с изображением с помощью stb.
- В десктопном OpenGL в отличие от ES версии по ходу дела можно использовать как современные шейдеры, так и устаревшие
glBegin/glEndодновременно. На мобильных устройствах OpenGL ES такого делать не позволяет.
Понедельник (вечер, за четыре дня до дедлайна)
- Понял, что QtCreator использует какие-то свои библиотеки плюс какие-то из msys2, а я больше привык к Visual Studio. Скачал FreeGLUT и прописал его в CMakeLists.txt.
- Сделал проект для Visual Studio и заставил его работать. Это получилось только после того, как я переставил свой Visual Studio, потому что там не было основного сборщика и он подцеплял какие-то настройки из msys2. Удалось исправить только после обнуления переменной окружения Path и запуска генератора cmake из-под vcvarsall.bat.
Вторник (три дня до дедлайна)
- Разбил программу на компоненты:
Application,Sprite,Image,Texture,Mesh,Shaderи так далее. - Окошко всё ещё пустое, ничего не рисуется, долго думал, как «прикрутить» нестатический C++ метод
Application::renderкак Сишный callback в методеglutDisplayFunc(). Кстати, через пару месяцев нашёл метод — передать указатель на экземпляр своего класса черезglutSetWindowData()/glutGetWindowData(), чтобы не использовать синглтон.
Среда (с утра до обеда, два дня до дедлайна)
- Наконец-то нарисовал спрайт с текстурой по нужным мне пиксельным координатам. Решил на этом остановиться: закрашиваю фон красным, рисую один спрайт.
- Подключил библиотеку glm, чтобы не умножать матрицы с векторами руками.
- Создал класс
Camera. - Сначала хотел сделать стандартный макрос
CHECK_GL_CHECK(glFunction), но в итоге прикрутил вывод ошибок в консоль с помощьюglDebugMessageCallback(). - Вечером добавил вычисление и рисование FPS и frametime. Очень странная установка позиции для вывода текста с помощью
glutBitmapString(). С цветом текста разобраться не удалось. Было бы здорово делать через freetype, про которую у меня написано много статей, но время поджимает, да не очень-то и хочется.
Четверг (один день до дедлайна)
- накануне много думал про вращающееся колесо с картинками. Хотел сделать физическое колесо с массой и инерцией для запуска и остановки, но решил не заморачиваться и сделать горизонтальную модель ленты с индексами текущей ячейки от 0 до n, индекс типа float, целая часть которого — текущая ячейка, а дробная — её смещение от нуля до единицы. Отдельно идёт класс View, который по данным от модели рисует иконки. Для эффекта закруглённости решил сверху наложить маску с затенением сверху/снизу и бликом посередине. Вроде должно сработать.
- под вечер сделал подобие колеса из четырёх иконок и решил собрать программу из того, что было.
- для этого привлёк настоящего проектировщика зданий для рисования маски с отверстием посередине, включил поддержку RGBA и цвет для вершин, добавил надпись START со сменой цвета, про маску с тенью успешно забыл.
Пятница (дедлайн)
- С утра пораньше сделал вращение колеса с плавной остановкой. Накануне придумал способ — крутимся с постоянной скоростью, за секунду до финала начинаем замедление с помощью формулы равнозамедленного движения.
- Вынес создание спрайтов с кешированием текстур в отдельный класс.
- Добавил обработку клика на кнопку.
- В итоге поставил Ubuntu на Hyper V виртуальную машину, установил нужные библиотеки через apt, написал инструкцию в Readme, убедился, что всё работает, загрузил изменения с виртуальной машины через SFTP на винду и в GitHub.
- Под винду включил статическую линковку в MSVC, чтобы не было нужды в .dll-файлах.
- Собрал исходники, собрал бинарники, отдал на проверку, гештальт закрыт!
Вторник (отклик от компании)
- Используются шейдеры, но при этом нет эффектов.
- Сторонние библиотеки STB и GLM, при этом GLM используется только для одной функции,
а STB для другой.
Оставлю эти замечания без комментариев, менять ничего не буду.
Для представления о том, что получилось, приведу скриншот (работает под любыми современными ОС):
Теперь это ещё один мёртвый проект на GitHub, по которому будут учиться AI, хе-хе-хе. Вы тоже можете составить своё мнение по этому «проекту» здесь в комментариях или в виде Merge Request к проекту. Для желающих увидеть ту самую версию, полученную «заказчиком», я поставил тег first_release в репозитории.
Текирова, Кемер, Турция — поездка на неделю
Писать или нет?, — думал я. По дороге в аэропорт провожающий гид «обрадовал», что рейс будет «Анталия-Махачкала», а не «Анталия-Петербург». И это ещё везение — кому-то до нас достался Новосибирск или Самара. «Точно писать!» — это сигнал свыше. Махачкала — это как будто Россия, но Дагестан, а достаточна ли у меня длина рукавов и штанин для посещения данной местности — я не очень уверен.

Итак, мы купили относительно недорогой тур в трехзвездочный отель Турции на семь дней. Что сказать, отель так себе, но радушие хозяев и местная живность в лице немецкой овчарки Беллы, рыжего кота, желтоглазой кошки и четырёх озорных котят подкупают, поэтому о минусах отеля писать не буду. Мы славно ели, крепко спали, подкармливали зверушек на завтрак и ужин. В отеле у нас всё прошло хорошо.




От отеля до пляжа примерно километр пути, лежаки бесплатно предоставляет местное кафе при условии покупки у них чего-нибудь, но это неточно — иногда мы занимали лежаки просто так.
Жили мы в городке Текирова, почти на краю Кемерской губернии и на экскурсии нас забирали первыми и возвращали последними (иногда наоборот). Из-за этой особенности водителям было лениво отвозить нас так далеко от Анталии, и они дважды пытались «сбагрить» нас товарищам, которым было по пути. Один раз нам удалось от такой пересадки отбиться, в другой — нет.
Ощущения, когда ты последний пассажир ночью в автобусе с незнакомыми турецкими мужиками — незабываемое. Особенно они обостряются после рассказа о беженцах-наркоманах из Сирии которые могут и ножом пырнуть, плюс ИГИЛ — всё ещё действующая организация, до которой ехать километров пятьсот.
По пути в аэропорт, к счастью, ситуация поменялась и рейс снова стал Анталия — Санкт-Петербург и все радостно захлопали, так что в Махачкалу, хвала Аллаху, попасть не суждено. Потому что специально в Дагестан я никогда бы не поехал.
Итак, насчёт экскурсий раздумья такие: больше их покупать не будем, арендуем машину/мопед и прокатимся по Кемерскому краю самостоятельно. Кстати, вот вам полезный совет: открываете сайт с названием местного тур оператора (Marş Travel, Şereşe Travel, Ginza Travel и т.д.) и требуете, чтобы экскурсию вам продали по интернет цене, иначе продаван называет цену, какая придёт в его светлую темноволосую голову. Мы были на экскурсии, где цена варьировалась от 25 до 40 баксов за человека, причём состав и условия экскурсий был одинаковыми. Мы купили несколько поездок: хамам, Демре-Мира-Кекова, бухта Порто Дженевиз, развалины города Перге, теперь по порядку о каждой поездке без прикрас.
Хамам
Отвозят на маршрутке в общественный хамам. Впервые был в очереди в бане, в целом хамам — это хорошо и обязательно к посещению а начале отпуска, только не этот конкретно, лучше бы взяли хамам в соседнем отеле. На обратном пути водитель пытался нас пересадить в другую маршрутку, но там не хватило сидячих мест, так что удалось отбиться с небольшим скандалом. Цена двадцать баксов с человека. С нами ехали те, кто взял за 18 баксов и за 25, так что делайте выводы.
Демре Мира Кекова
Посещение трёх городов и церкви Николая Чудотворца, также известного как Санта Клаус.
Оказалось, Санта не живёт с женой на Северном Полюсе, а давно умер, и власти скрывают! Перед покупкой экскурсии вам льют в уши, что вы поплывёте на судне со стеклянным дном обозревать руины древних городов, по факту получаются два грязных окошка, в которые ничего не видно кроме зелёной воды. Глумиться про религию не буду (это не одобряют жена и УК РФ), но давно я не видел такого коммерциализированного подхода к религии, особенно в сфере продаж реквизита. Из хорошего — посещение церкви Святого Николая Чудотворца. Монументальное и очень древнее строение. Удивительно, как в начале нашей эры смогли возвести подобное сооружение.
Бухта Порто Дженевиз
Прогулка на кораблике с купанием по трём бухтам: два раза по часу и один на полчаса. Старт корабля из Адрасана. Рекомендую вместо этого купить экскурсию на турецкие Мальдивы — Сулуада. Там вода чище, виды красивее и в целом лучше. Экскурсия запомнилась знакомством с байкерами из Нижнего Новгорода, которые своим ходом через Грузию за шесть дней доехали до Кемера. Из неприятного — тётка в маршрутке, которая заняла чужое место и внезапно забыла русский язык. Так мы и познакомились с байкерами.
Отдельно хочу отметить Адрасан — уникальное место, где кораблики припаркованы кормой прямо к пляжу, вереница кораблей километра два длиной. Вид грандиозный. Если там не были, обязательно побывайте.
Перге
Четыре события по цене одного и пятое в подарок. Сначала везут в парк к верхнему Дюденскому водопаду. Потом часик гуляем по развалинам древнего города Перге. Потом — ужин вкуснейшими котлетками-кюфте, много-много пахлавы, турецкий чаёк. Далее отвозят в «Land of legends» с шоу фонтанов, красивым замком Nickelodeon и элитными магазинами. В завершение программы — вишенка на торте: пересадка посреди ночи из комфортного автобуса в ссаную маршрутку с двумя неизвестными турками, потому что водителю лениво далеко ехать, зато бакшиш брать не лениво.
Кемер
Три года назад мы были в Кемере и решили его посетить самостоятельно. Ездили в самую жару на автобусе номер 8, если правильно помню. Вспомнили, что там очень неудобный заход в море через гальку и на пляже не очень-то полежишь. Так что мы были в Кемере один раз. Рядом, кстати, располагается античный ликийский город Фаселис, но туда мы не добрались.
В целом это небольшое путешествие очень понравилось и оставило самые приятные воспоминания — когда ещё понежишься на солнце, когда дома 16 градусов «тепла» и дождь. Это был не очень логичный поступок, когда мы с женой одновременно безработные, но считаю все было не зря, зимой будет что вспомнить.
Небольшая новость
Всем привет! Всякому программисту положено иметь pet-проект, который он холит, лелеет и делает в свободное время.
Когда я задумался о таком, оказалось, что мой pet-проект — это собственно сайт blog2k.ru, для которого я написал свою тему для WordPress и поддерживаю собственный WordPress плагин со всякими полезными плюшками.
Буквально сегодня выложил в открытый доступ на github исходники своих наработок:
- тема для WordPress этого сайта: b2k-theme
- плагин с полезным функционалом: b2k-tools
- виджет, который при добавлении в область title sidebar, показывает список постов c текущей категорией или тегом: wp-index-widget
- плагин для виджета отображения погоды: yowindow-widget
Работу плагина wp-index-widget можно увидеть, например, здесь.
Всё выложено под лицензией MIT, можно модифицировать, изменять, брать любую часть и даже использовать в коммерческих целях.
Коммиты и форки всячески приветствуются и не осуждаются. Пул реквесты также, возможно, будут приняты. Enjoy!
Пул потоков с запуском функций с переменным количеством параметров
Всем привет! Внезапно оказался без определённого места работы и в свободное время мучаю ИИ по поводу возможных задач и вопросов на собеседованиях по C++, и некоторые задачи делаю самостоятельно.
Недавно я попросил ИИ сделать пул потоков. Я его написал заранее, но захотелось проверить, где я мог ошибиться.
ИИ написал нерабочий код, но с интересной идеей: запускать вместо стандартного std::function<void()> функции с параметрами с помощью std::packaged_task и variadic templates. Меня этот так вдохновило, что я решил таки сделать этот код рабочим. И сделал!
Кстати, мой код не нравится ИИ — он предлагает его переделать на std::condition_variable и, возможно, он прав, а я написал ерунду, таков путь!
#include <vector>
#include <atomic>
#include <thread>
#include <mutex>
#include <functional>
#include <deque>
#include <optional>
#include <future>
#include <iostream>
class ThreadPool {
public:
/// По умолчанию количество потоков равно количеству аппаратных потоков
ThreadPool(size_t numThreads=std::jthread::hardware_concurrency()) {
m_threads.reserve(numThreads);
for (size_t i = 0; i < numThreads; ++i) {
m_threads.emplace_back([this](){ runLoop(); });
}
}
// Принимаем на входе функцию и её аргументы, на выходе автоматически
// оборачиваем результат работы функции в std::future
template<typename... Args>
auto runTaskAsync(auto f, Args&&...args) {
// Выясняем возращаемый тип у функции
using return_type = std::invoke_result_t<decltype(f), Args...>;
// Заворачиваем функцию с переменным количеством аргументов в
// std::packaged_task, у которого можно получить std::future<return_type>
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<decltype(f)>(f), std::forward<Args>(args)...)
);
// Получаем std::future
auto res = task->get_future();
if (m_Running) {
std::unique_lock lock(m_guard);
// Добавляем задачу в очередь на выполнение
m_tasks.push_back([task](){(*task)();});
// Уведомляем ожидающие потоки
m_hasTask = true;
// Может тут надо использовать notify_one (?)
m_hasTask.notify_all();
}
return res;
}
// Вызываем функцию синхронно и возвращаем результат
template<typename...Args>
auto runTaskSync(auto f, Args &&...args) {
return runTaskAsync(f, std::forward<Args>(args)...).get();
}
~ThreadPool()
{
// Устанавливаем флаг остановки потоков
m_Running = false;
// Очищаем очередь задач
{
std::unique_lock lock(m_guard);
m_tasks.clear();
}
// Обманом :-) выводим потоки из режима ожидания
m_hasTask = true;
m_hasTask.notify_all();
// Для каждого потока
for (auto &thread : m_threads) {
if (thread.joinable()) {
// Дожидаемся завершения работы
thread.join();
}
}
}
private:
using Task = std::function<void()>;
void runLoop() {
while (m_Running) {
// Ждём задачу
m_hasTask.wait(false);
std::optional<Task> task;
// Забираем задачу из начала списка
{
std::unique_lock lock(m_guard);
if (!m_tasks.empty()) {
task = m_tasks.front();
m_tasks.pop_front();
}
}
// Задача есть, исполняем
if (task) {
(*task)();
}
else {
// Отдаём процессорное время другим потокам
std::this_thread::yield();
}
}
}
// Вектор потоков
std::vector<std::thread> m_threads;
// Атомарный флаг остановки потоков
std::atomic_bool m_Running{ true };
// Атомарный флаг наличия задачи
std::atomic_bool m_hasTask{ false };
// Очередь задач
std::deque<Task> m_tasks;
// Мьютекс для защиты очереди задач
std::mutex m_guard;
};
int main()
{
// Создаём пул потоков
ThreadPool mgr;
// Первая задача на две секунды, которая возвращает строку
auto func = [](const std::string &s) {
std::cout << "Long task1 begin..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "Long task1 end..." << std::endl;
return s;
};
// Вторая задача на пять секунд, которая ничего не возвращает
auto func2 = []() {
std::cout << "Long task2 begin..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(5));
std::cout << "Long task2 end..." << std::endl;
};
// Запускаем первую задачу с параметром
auto result1 = mgr.runTaskAsync(func, "task1 result");
// Запускаем вторую задачу без параметров
auto result2 = mgr.runTaskAsync(func2);
// Получаем результат выполнения первой задачи и выводим в консоль
std::cout << "Task1 result = " << result1.get() << std::endl;
// Ждём вторую задачу
std::cout << "Wait task2 result" << std::endl;
result2.wait();
}
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <future>
#include <memory>
#include <stdexcept>
class ThreadPool {
public:
// Конструктор, создающий указанное количество потоков
ThreadPool(size_t threads) : stop(false) {
for(size_t i = 0; i < threads; ++i) {
workers.emplace_back([this] {
for(;;) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this]{ return this->stop || !this->tasks.empty(); });
if(this->stop && this->tasks.empty())
return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
}
// Добавление задачи в пул
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type> {
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// Не добавляем новые задачи после остановки пула
if(stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
tasks.emplace([task](){ (*task)(); });
}
condition.notify_one();
return res;
}
// Деструктор, останавливающий все потоки
~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for(std::thread &worker: workers)
worker.join();
}
private:
std::vector<std::thread> workers; // Рабочие потоки
std::queue<std::function<void()>> tasks;// Очередь задач
std::mutex queue_mutex; // Мьютекс для синхронизации доступа к очереди
std::condition_variable condition; // Условная переменная для уведомлений
bool stop; // Флаг остановки пула
};
Буду признателен, если вы укажете на возможные ошибки и недочёты в моём коде.