Многие не понимают — что такое «дополненная реальность». Смотрите видео и все поймете (на самом деле, там всего лишь проектор, песочница и Microsoft Kinect, который строит 3D модель окружающего мира).
Конструктор, деструктор и автоматический стек в C++
С удивлением узнал об интересном способе использования стека в нестандартных целях. Посмотрите внимательно на код ниже.
Его фишка в том, что класс Sample в конструкторе сохраняет предыдущий инстанс типа Sample, а в деструкторе — восстанавливает. При этом метод Sample::instance() всегда будет возвращать текущий объект типа Sample.
Не имею ни малейшего понятия — зачем это может вам понадобиться, но мне пришлось столкнуться с таким впервые, так что спешу поделиться с общественностью.
Пример использования такого функционала под катом. (в комментариях указано — какой instance сейчас текущий)
Креативная реклама кухни в иностранной газете

По клику на картинке можно посмотреть фото реальной газеты (UPD: Ссылка нерабочая).
Панорамы Петербурга с вертолета (ОСТОРОЖНО — ЗВУК!)
Потрясающие виды на Санкт-Петербург с высоты вертолетного полета.

Для просмотра просто кликните по картинке или заходите под кат.
Семеричный куб в перспективной проекции
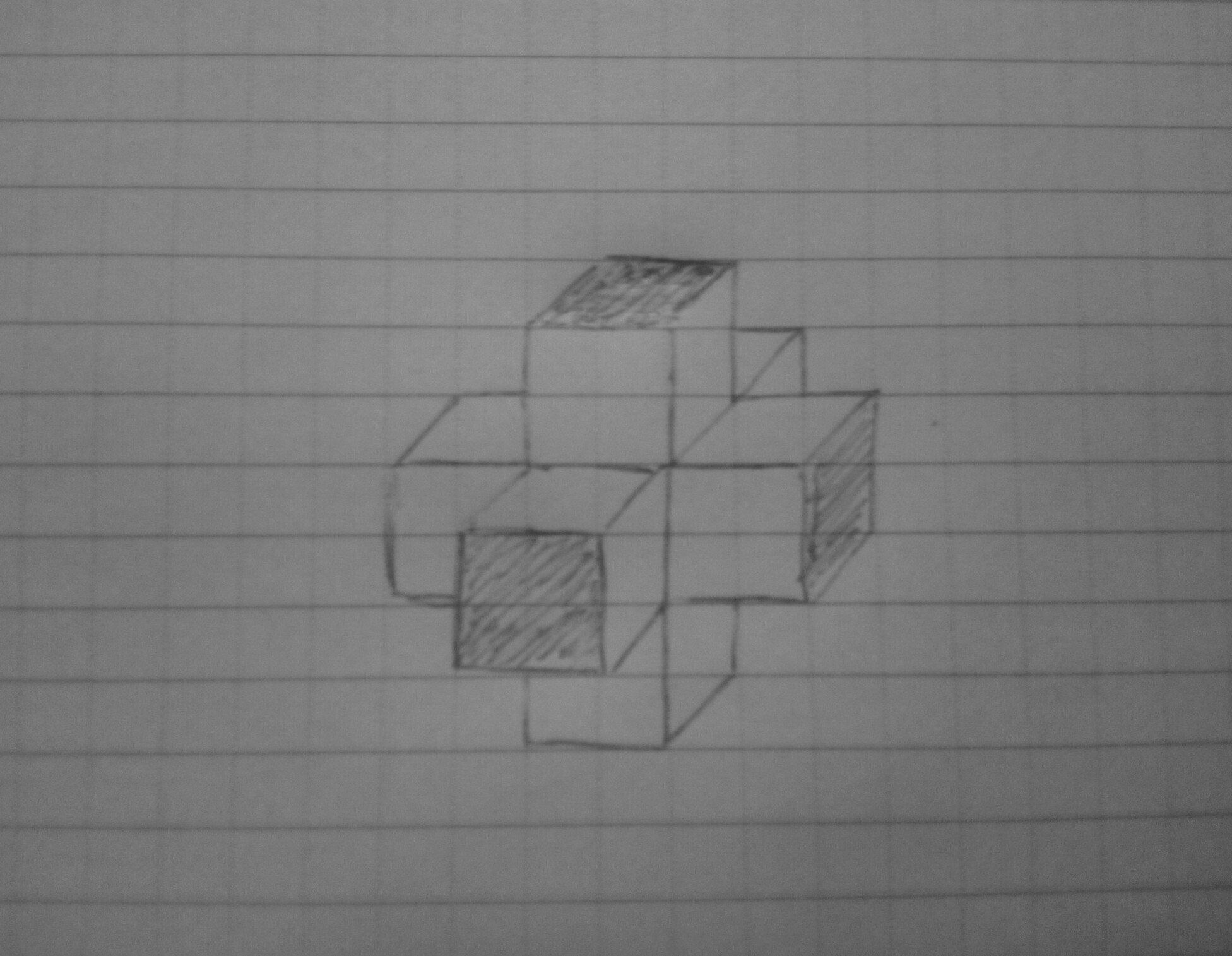
Баловался в школе тем, что в тетрадках рисовал подобную ерунду. Оказалось, что это семеричный куб в изометрической проекции. Теперь появилась возможность увидеть этот объект в движении. Представляю вам семеричный куб в перспективной проекции на двумерную плоскость вашего монитора. Между прочим, у этого симпатичного объекта три оси измерения: ось X, ось Y и время, которое зациклено по кругу.