Всем привет! Мне нужно срочно поделиться с миром, какой я весь из себя молодец, нет сил больше держать это в себе. В общем, встала задача восстановить данные с жёстких дисков сервера фирмы, где я раньше работал. Так исторически сложилось, что сервер после развала фирмы по договорённости с руководством переехал ко мне домой. Родилась идея восстановить данные с сервера. Сервер давно не включается, в нём старые HDD IDE диски. Всего дисков три штуки: 160Gb, 320Gb и 1.5Tb. Файловая система на них ext2fs или часть RAID массива. Была идея подключить их к виртуальной машине Debian и получить доступ к файлам.
Как я поступил изначально — купил переходник IDE->USB и попробовал подключить диск к компьютеру.

Ничего не получилось даже с отдельным блоком питания — отправил переходник обратно продавцу. Стало понятно, что подключить диски напрямую малой кровью не получится, значит, надо делать копию дисков и подключать к виртуальной машине виртуальные жёсткие диски с этих копий. Постепенно родился такой план решения задачи:
- Получить посекторные дампы с дисков в виде огромных файлов
- Получить виртуальные жёсткие диски с этих файлов и подключить их к виртуальной машине
- Получить доступ к файлам из этих дампов из виртуальной машины
Посекторные дампы дисков
Отнёс диски в специализированную контору, которая сделала посекторную копию двух дисков на принесённый мною новый SATA диск. Каждая копия обошлась мне в 1500₽. Новый SATA диск вышел в районе 4000₽. Через пару недель принёс диск с копиями домой, воткнул в компуктер и получил вот такую картину:
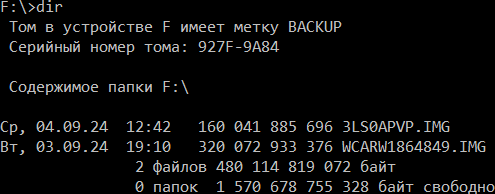
Второй файл оказался битый, потому что новый диск для хранения дампов оказался барахлом. НИКОГДА НЕ ПОКУПАЙТЕ Seagate ST2000VX000 — у меня он начал сыпаться после 19 часов работы. Так что сначала запустил команду для восстановления всех файлов, которая справилась за каких-то три часа:
chkdsk /F /R /X |
и приступил к следующему шагу.
Конвертирование дампов в виртуальные жёсткие диски для виртуальной машины и их подключение
Ни одна из известных мне виртуальных машин (VirtualBox, VMWare, Hyper-V) не поддерживает сырые данные в виде виртуального жёсткого диска, так что в процессе поиска решения, благодаря статье, наткнулся на бесплатную утилиту Startwind V2V Converter, при помощи которой и сконвертировал сырые дампы в .vdi (VirtualBox Disk) и .vmdk (VMWare Virtual Disk). Программа очень проста в использовании. Выбираем источник данных Local File, место назначения Local File. Потом тип файла и его подтип. Мне пришлось сделать два разных типа, потому что, как я писал выше, второй файл битый, и в формате .vdi VirtualBox его переварить не смогла, а вот в формате .vmdk вполне.
Виртуальную машину я использовал Oracle VirtualBox, просто потому что она бесплатная. Хотел использовать Hyper-V, встроенную в Windows 10 Pro, но она ни в каком виде не смогла подключить второй битый файл.
Подключение расписывать тоже не буду, покажу финальный скриншот:
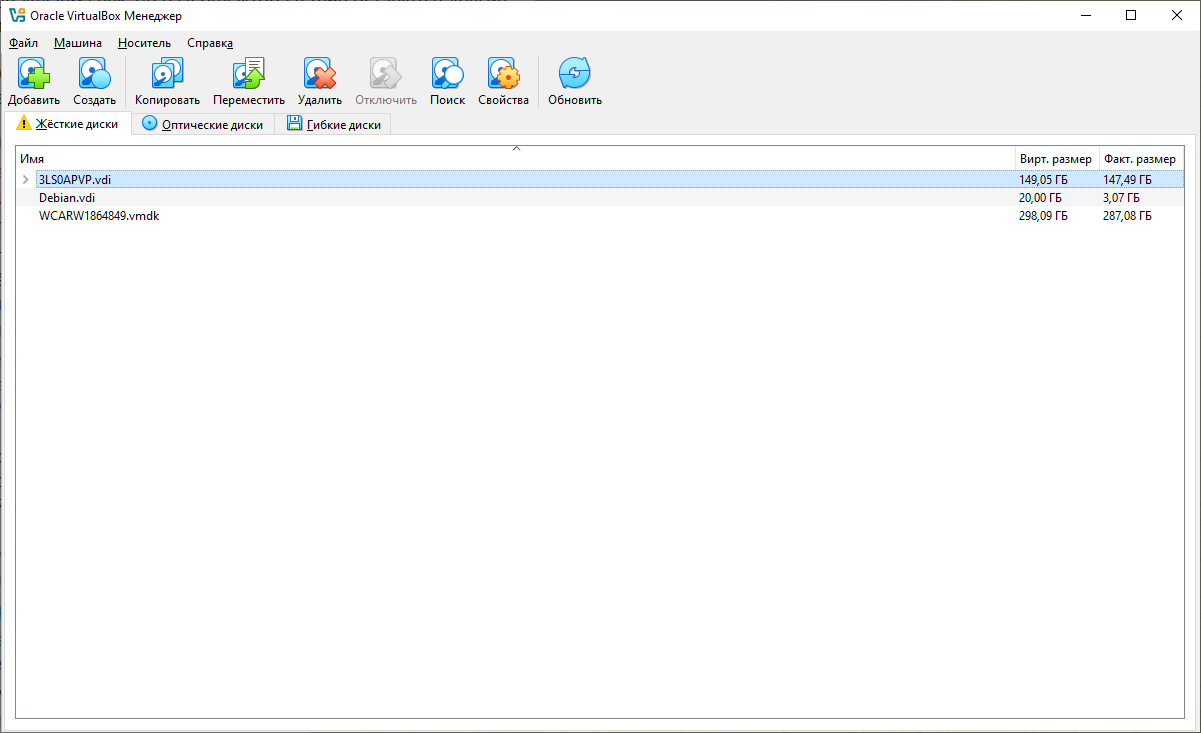
Финальный аккорд — получаем доступ к файлам
После подключения дисков и запуска Debian необходимо определить, куда они подключились. В линуксе это устройства /dev/sd[a-z], при этом /dev/sda уже занят. Значит, это диски sdb и sdc. Запускаем
fdisk -l /dev/sd[b,c] |
И получаем следующую картину:
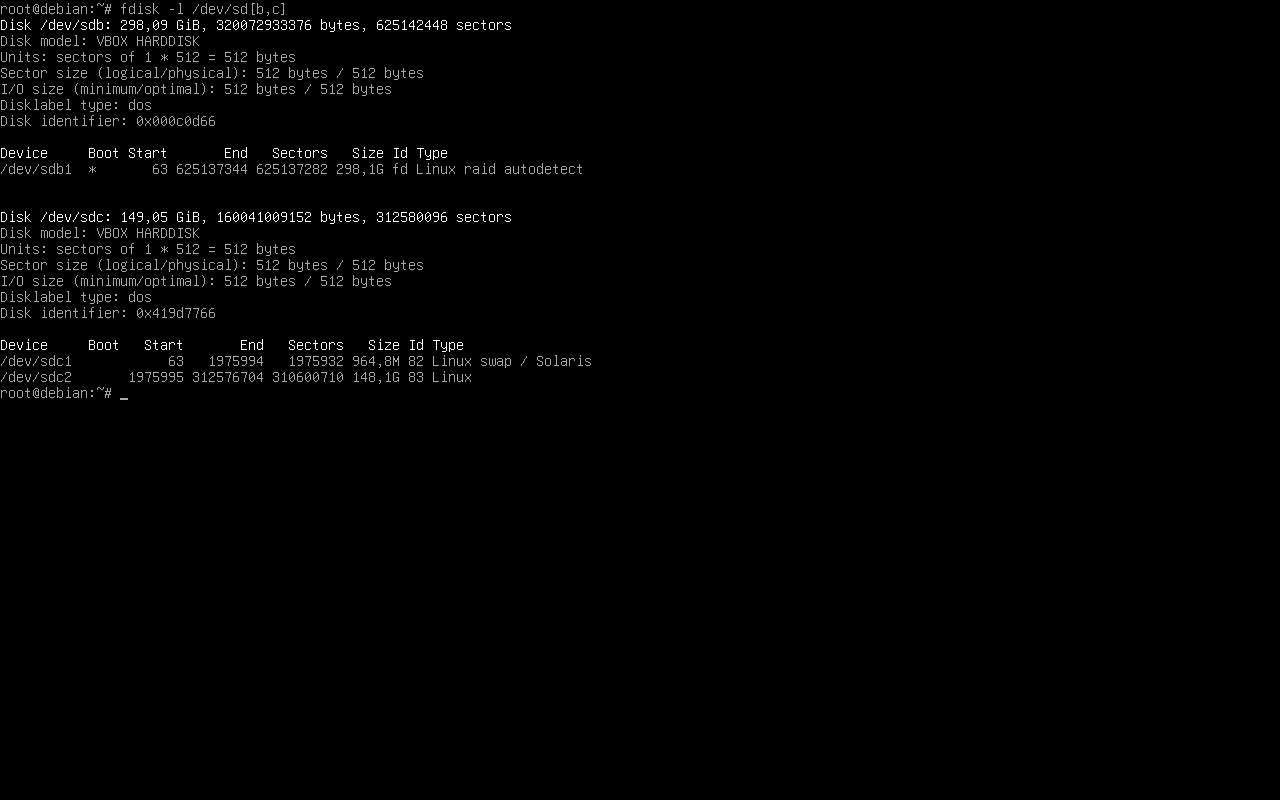
Отсюда следует, что /dev/sdc2 можно сразу монтировать командой:
mount /dev/sdc2 /mnt/memory-150 |
А на диске /dev/sdb располагается кусок raid массива. Я в них абсолютно ничего не понимаю, зато умею гуглить, и нашёл статью, как подключить один кусок из программного raid массива — тыц. Как бездумная, но опытная обезьянка, выполнил шаманство с запуском pvscan, mdamd, lvm2 и прочими командами, и у меня появилось устройства /dev/onraid/root /dev/onraid/shares /dev/onraid/var, которые я успешно смонтировал командами:
mount /dev/onraid/root /mnt/memory-300-root mount /dev/onraid/shares /mnt/memory-300-shares mount /dev/onraid/var /mnt/memory-300-var |
Всё, результат есть, файлы доступны, можно продавать исходники пустить ностальгическую слезу. Осталось проделать похожие процедуры с третьим диском на полтора терабайта, но у меня пока нет таких свободных объёмов. А потом можно подумать, что делать с этим добром, потому что самые свежие исходники там от 2010 года и выглядят местами очень наивно.
P.S. Кому интересно, устройство игрового движка Trickster Games