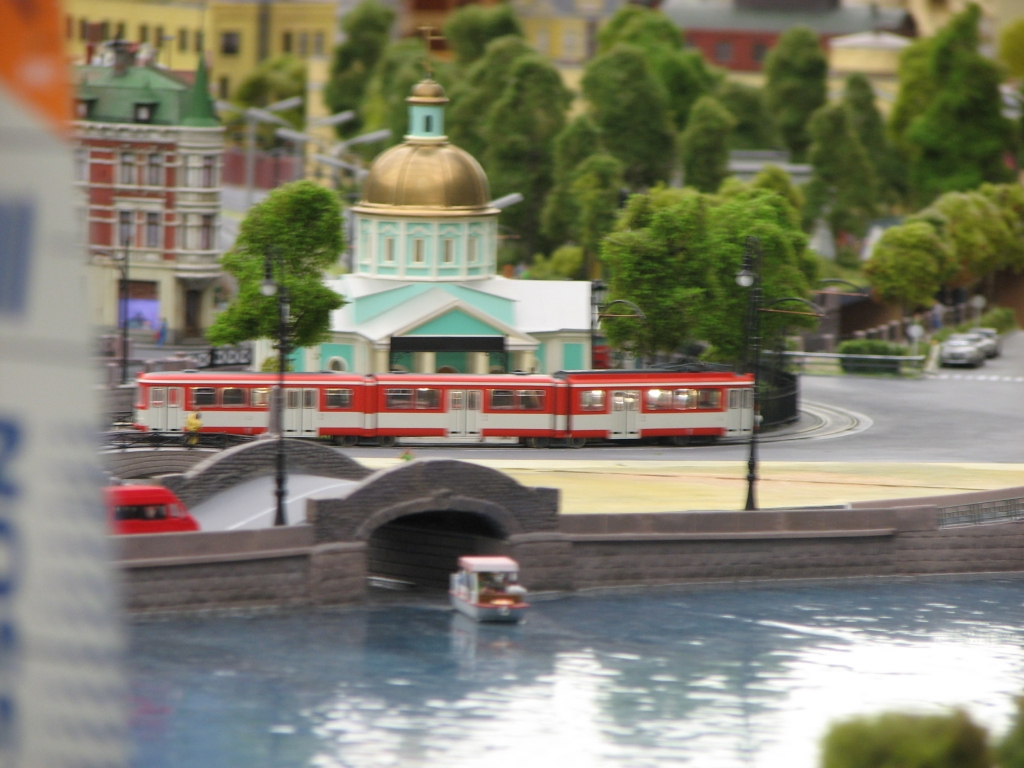Захотелось мне намедни создать GIF анимацию из набора фотографий. Фотографии вот такие (это между прочим анимация на библиотеке в Минске, если кто не знает):

Все они сфотографированы примерно из одной позиции примерно одного объекта. Если создать из этих фотографий анимацию (делал с помощью сайта gifmaker.me), то получится вот такая неприглядная GIF-ка:

Разумеется, это было мало похоже на анимацию, скорее на набор кадров. Так что пришлось вручную подгонять каждую фотографию к одному виду в графическом редакторе. Потратив на это три с лишним часа, стало понятно, что так дальше продолжаться не может — кадры скакали чуть меньше, но все равно очень заметно. Ведь фотографии отличаются не только сдвигом фотоаппарата относительно объекта, но и масштабом с искажением.
Обратился за помощью к хабра-сообществу и решение нашлось. Это программа Hugin и утилита align_image_stack, которая есть в установочном пакете этой программы.
Оно плохо работает, если кадров мало, но это лучше, чем ничего. Делюсь с вами, вдруг пригодится.
- устанавливаем программу Hugin (ссылка для скачивания)
- создаем файл проекта output.pto с помощью утилиты align_image_stack (align_image_stack.exe -p output.pto in_0.jpg in_1.jpg in_N.jpg). Названия файлов надо указывать по-одному, маска файлов программой не поддерживается.
- открываем получившийся output.pto в программе Hugin
- нажимаем «Объединить» (Hugin должен пересчитать контрольные точки для изображений), закрываем открывшееся после процедуры окно
- после этого кнопку «Создать панораму»
После нажатия кнопки «Создать панораму», откроется диалоговое окно, где надо указать папку для сохранения исправленных изображений. По умолчанию формат изображений TIFF.
Получаются вот такие изображения (можно их обрезать с помощью любого редактора, например IrfanView):

Создаем GIF-ку из получившихся фотографий:

P.S. Важный момент — лучше использовать оригинальные изображения с фотоаппарата, потому что они содержат информацию о фокусном расстоянии камеры, которое необходимо программе Hugin для правильной работы.